library(crmPack)
dose_grid <- c(1, 5, seq(from = 10, to = 200, by = 1))crmPack Training for Merck
Basic Training
March 31, 2026
Basic Training Outline 📦
- Motivation
- Model-based dose escalation design
- Example study design
- Calculating operating characteristics
- Backfilling cohorts
![]()
3+3 design
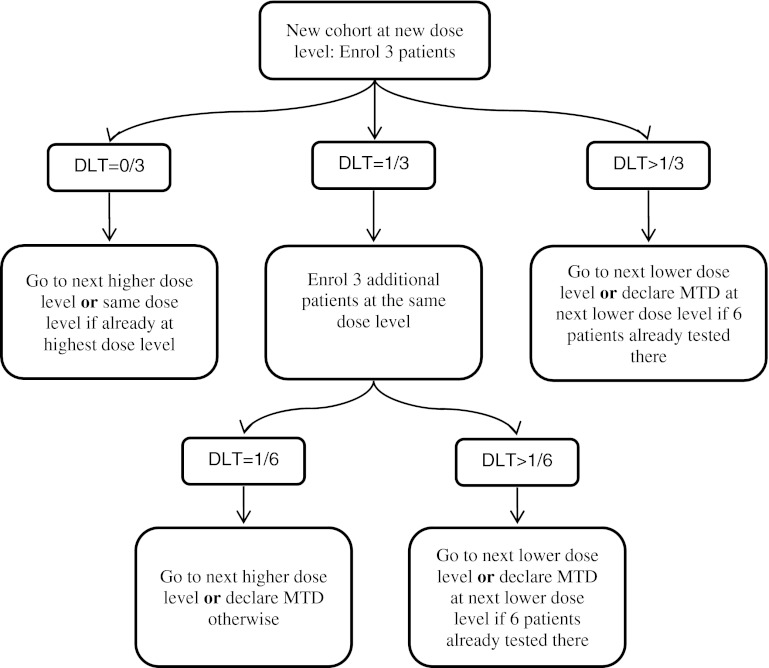
Figure taken from “Principles of dose finding studies in cancer: A comparison of trial designs”
Higher-level overview
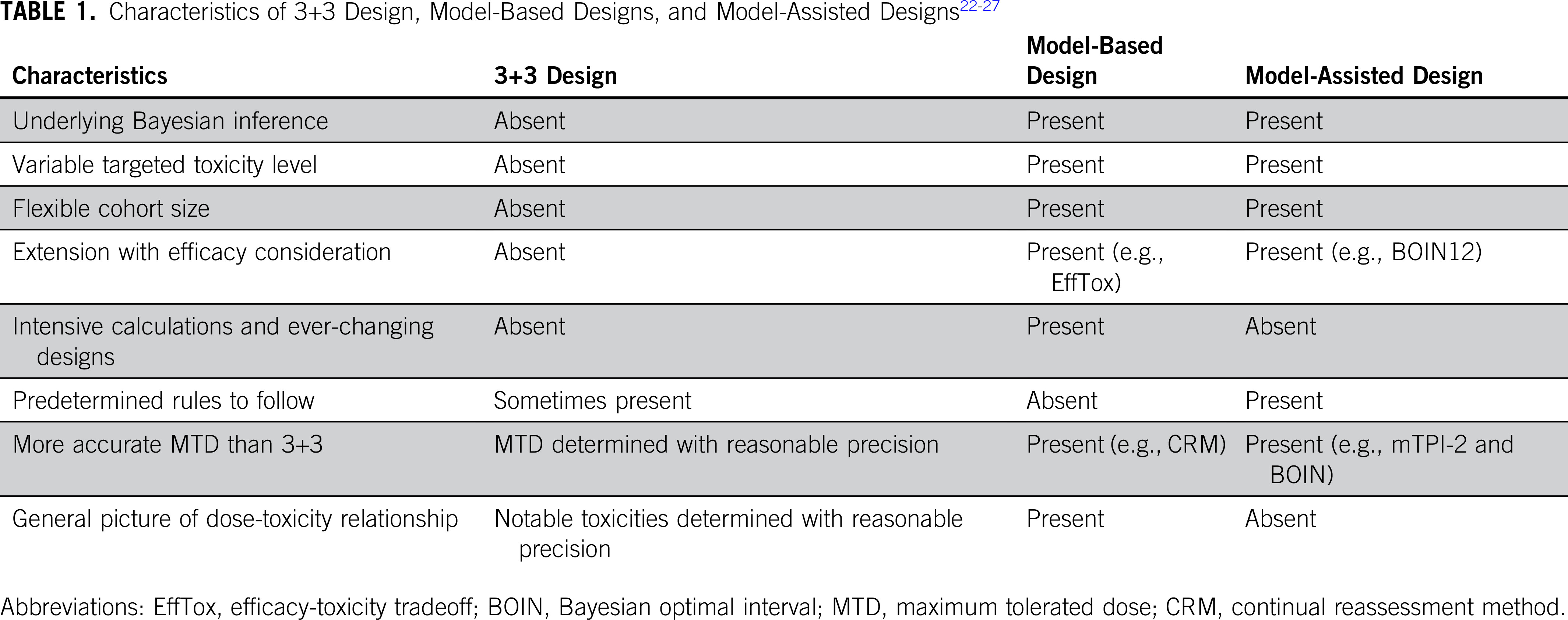
Table taken from “Moving Beyond 3+3: The Future of Clinical Trial Design”
Flow chart
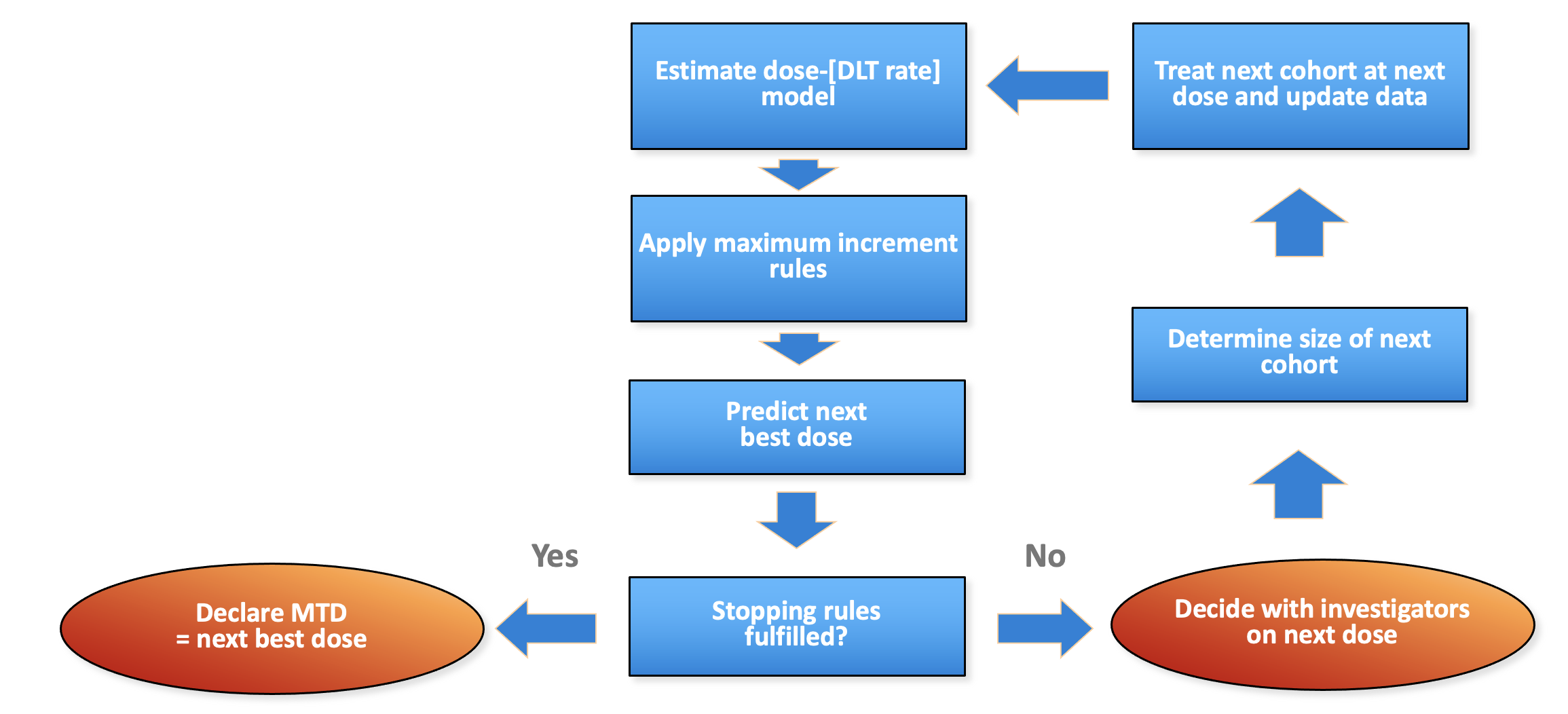
Generic flow chart for model-based dose escalation design
Package structure: parallel to flow
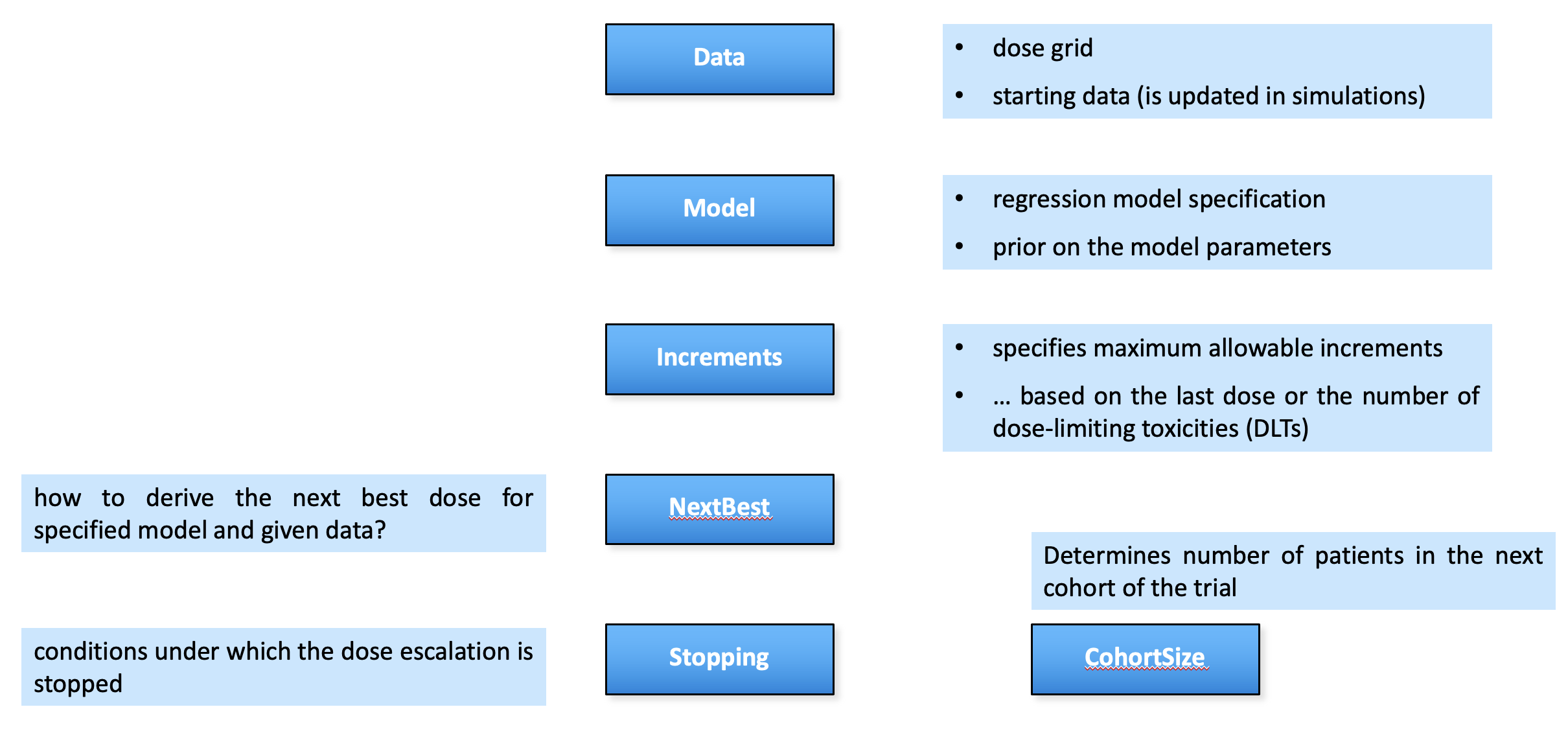
crmPack package structure parallels the flow chart
Framework in crmPack
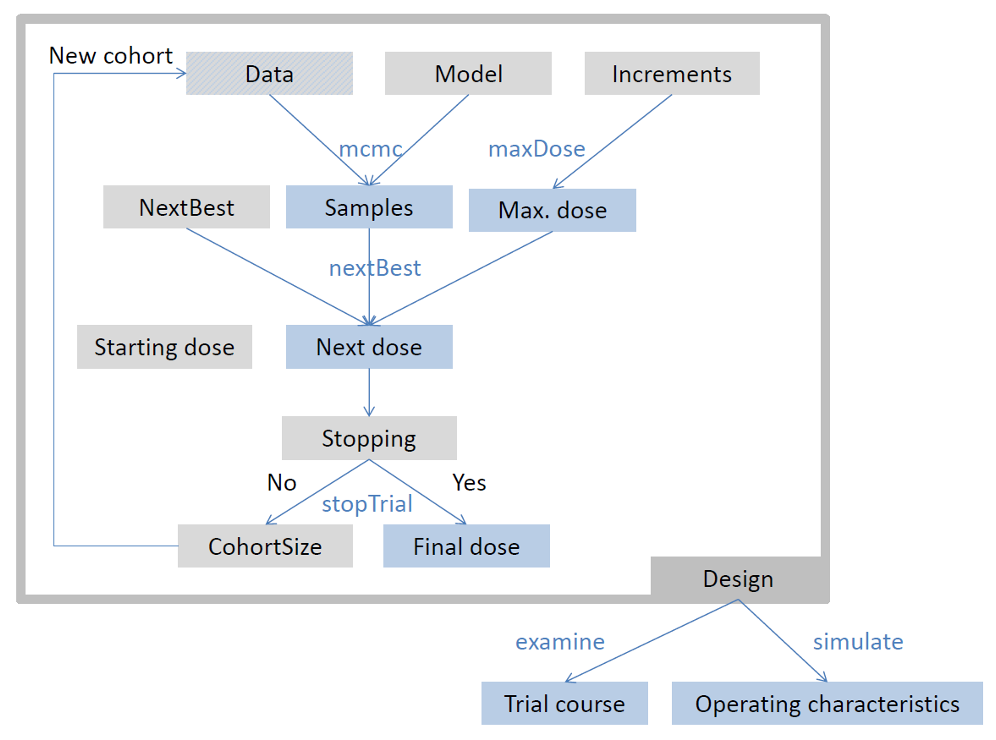
crmPack package framework
Adding a patient
We can “update” the Data object with the information of a patient treated at dose 10, who did not experience a DLT, and a patient at dose 20 with a DLT:
data <- empty_data |>
update(x = 10, y = 0) |>
update(x = 20, y = 1)And plot it:
plot(data)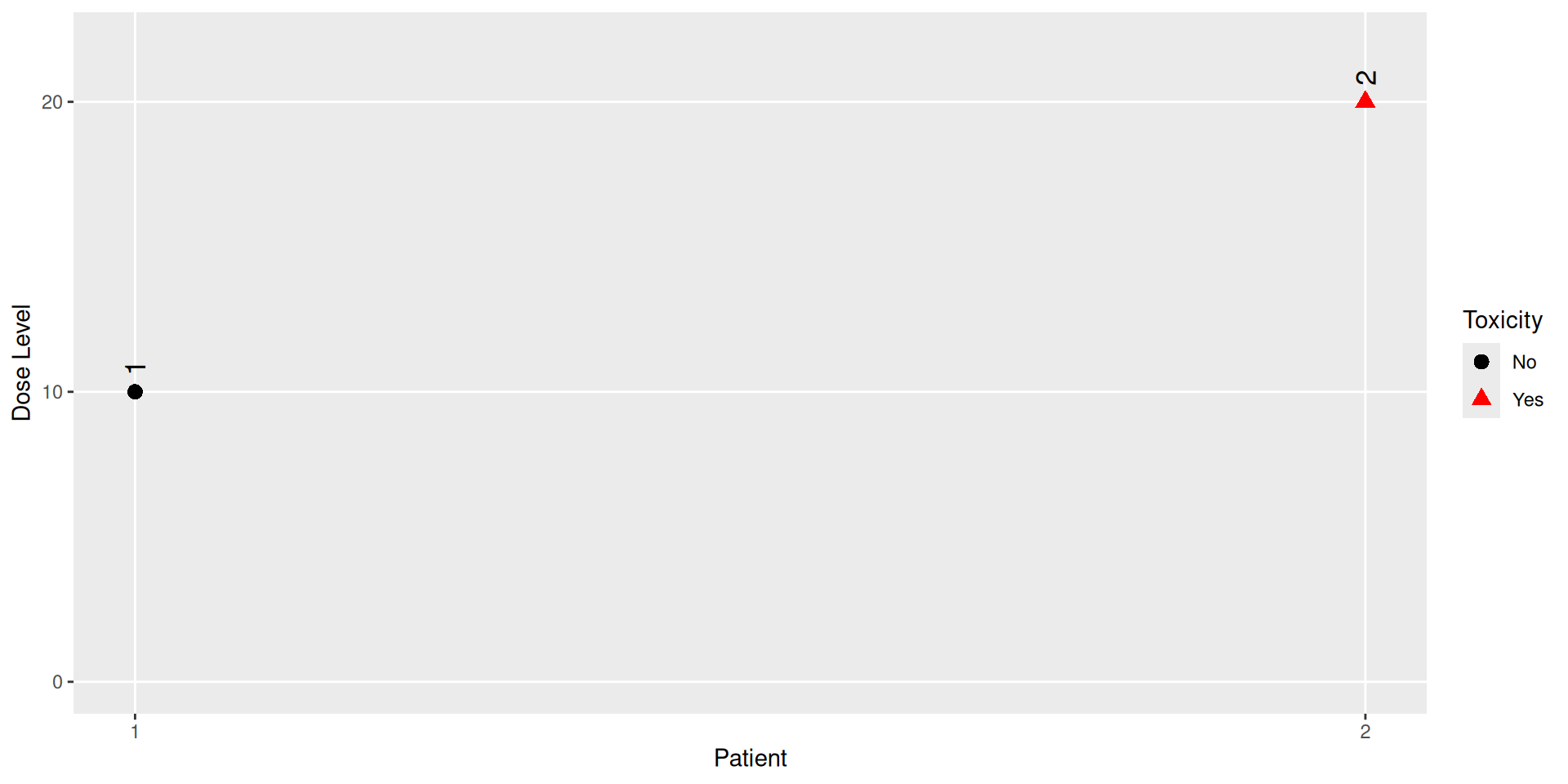
MCMC settings recommendations
- The default MCMC settings are:
- burn-in: 10,000
- step: 2
- samples: 10,000
- We just saw that we can use lower numbers during development
- Also the more complex the model, the longer the MCMC chain should be run
- The most important is to check the convergence of the MCMC chain:
names(posterior_samples@data)[1] "alpha0" "alpha1"alpha0_samples <- get(posterior_samples, "alpha0")
library(ggmcmc)
ggs_traceplot(alpha0_samples)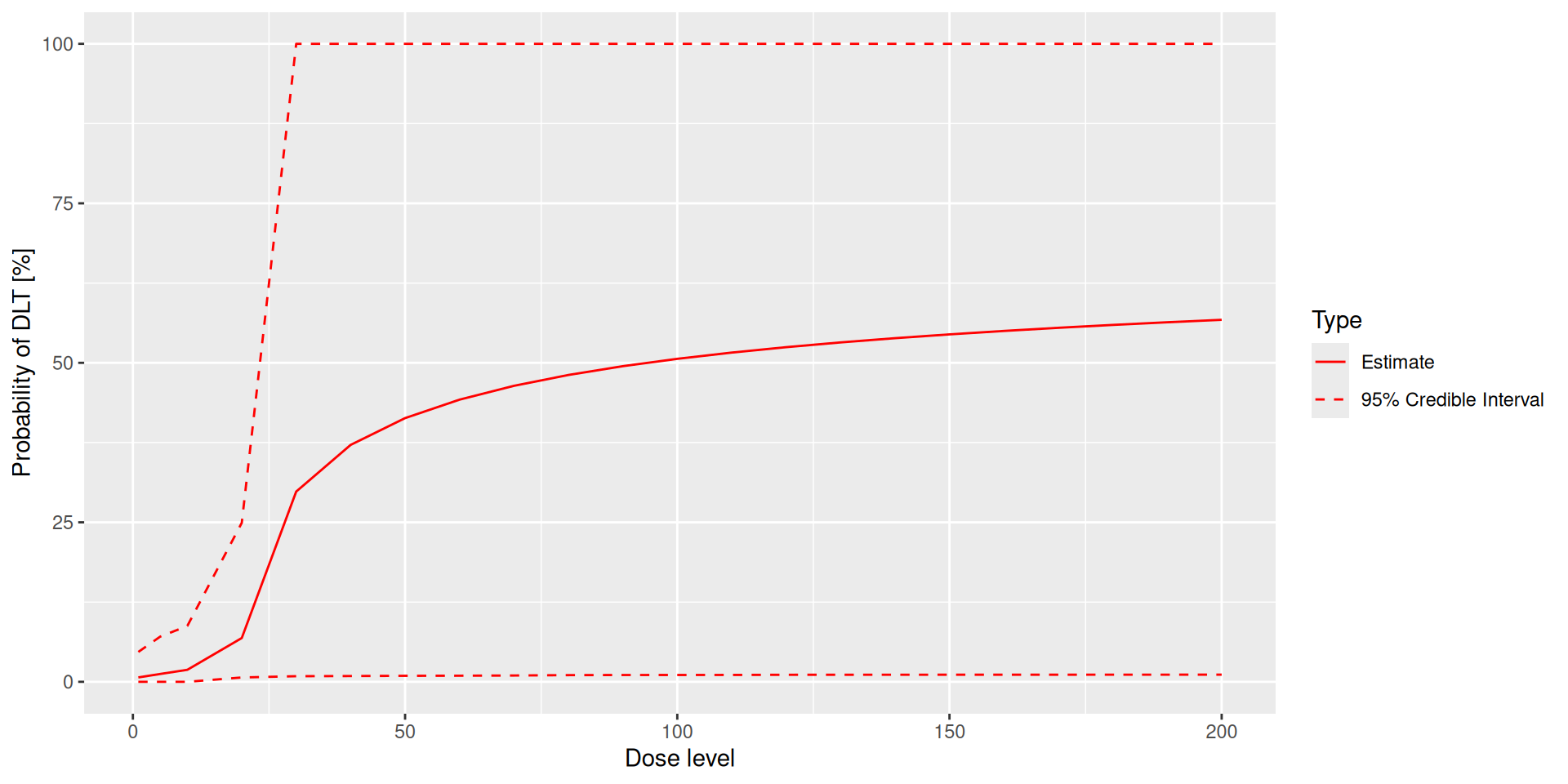
ggs_autocorrelation(alpha0_samples)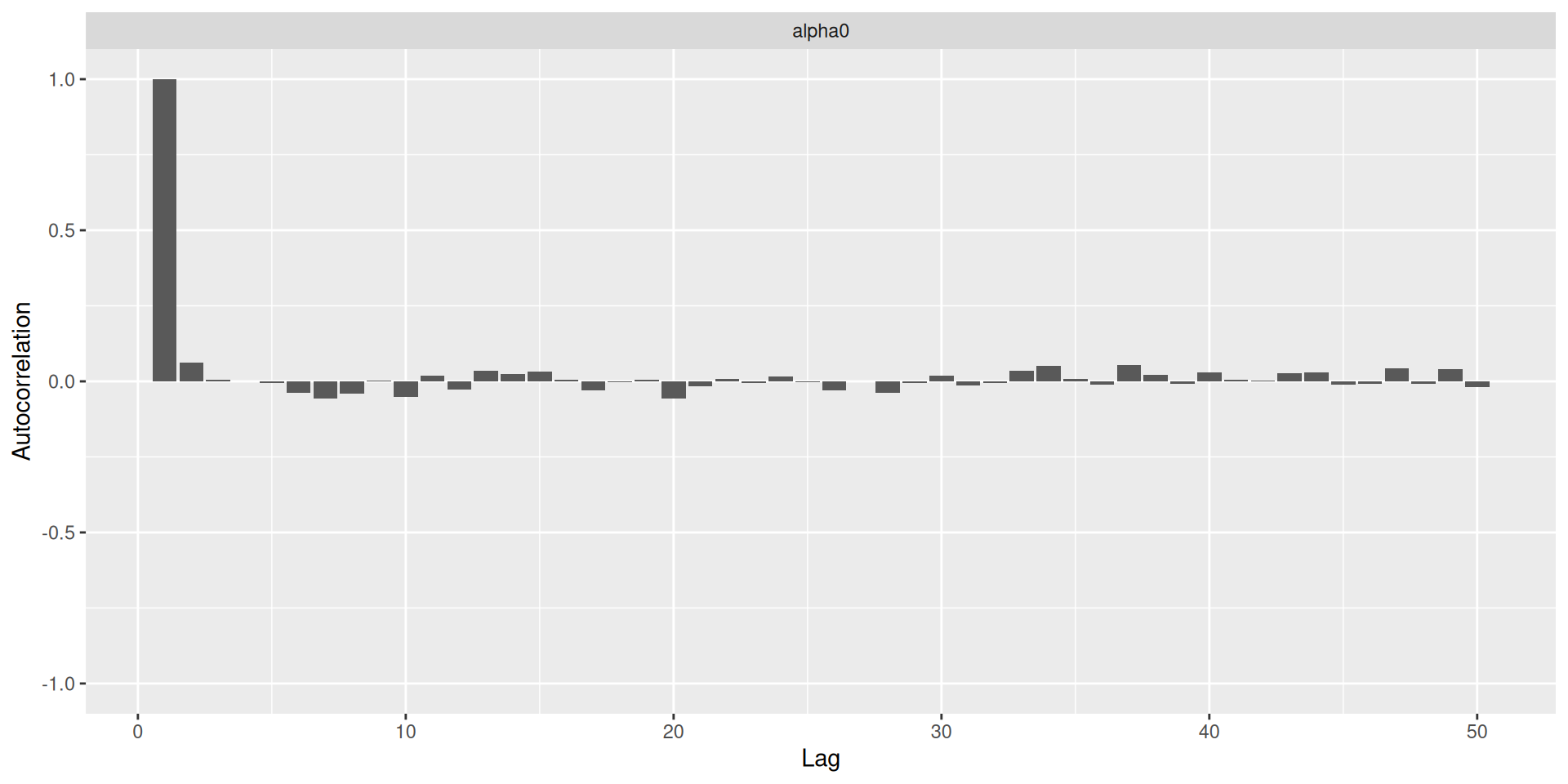
Plotting dose-toxicity curves: Prior
plot(prior_samples, model, empty_data)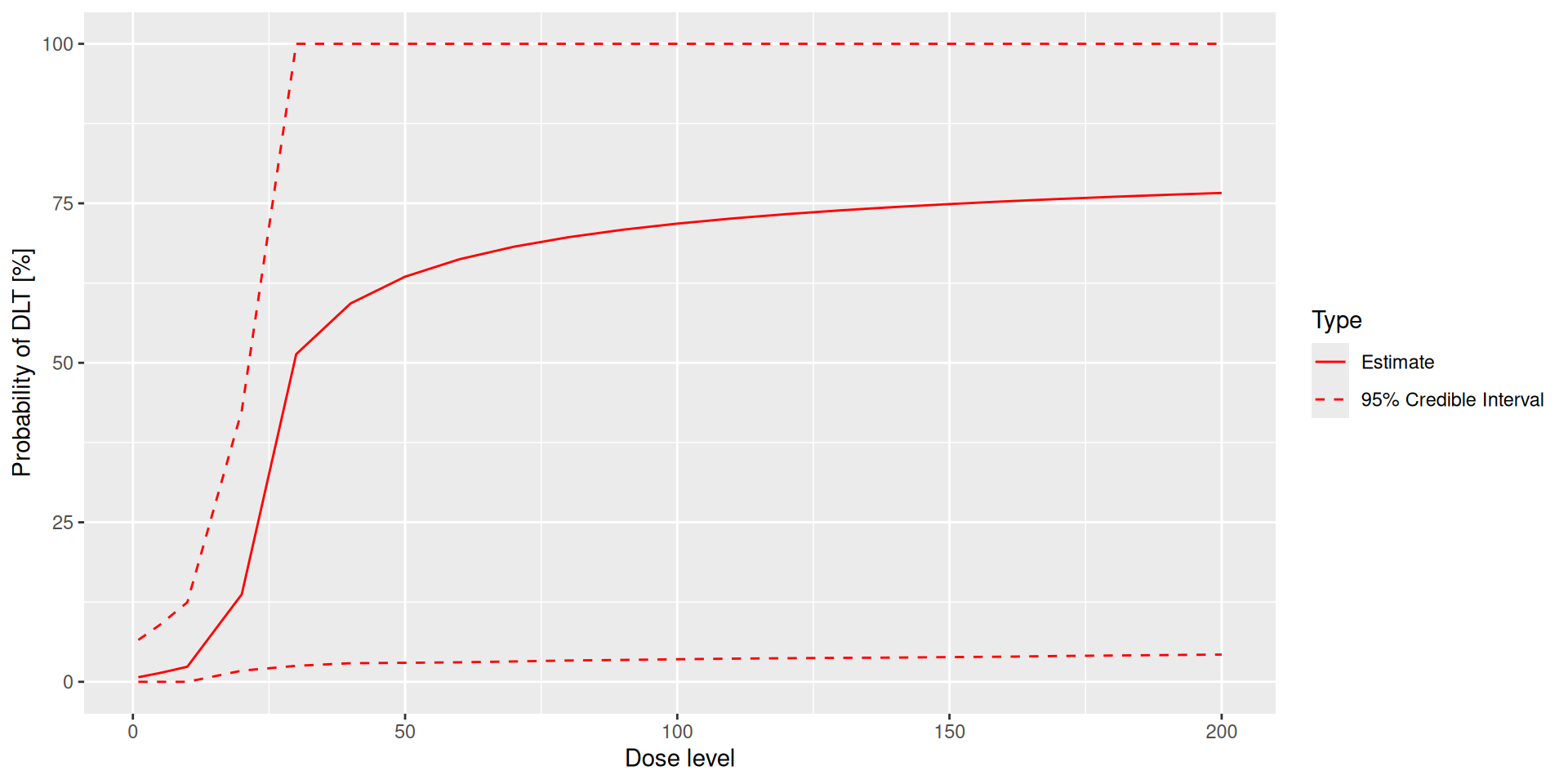
Plotting dose-toxicity curves: Posterior
plot(posterior_samples, model, data)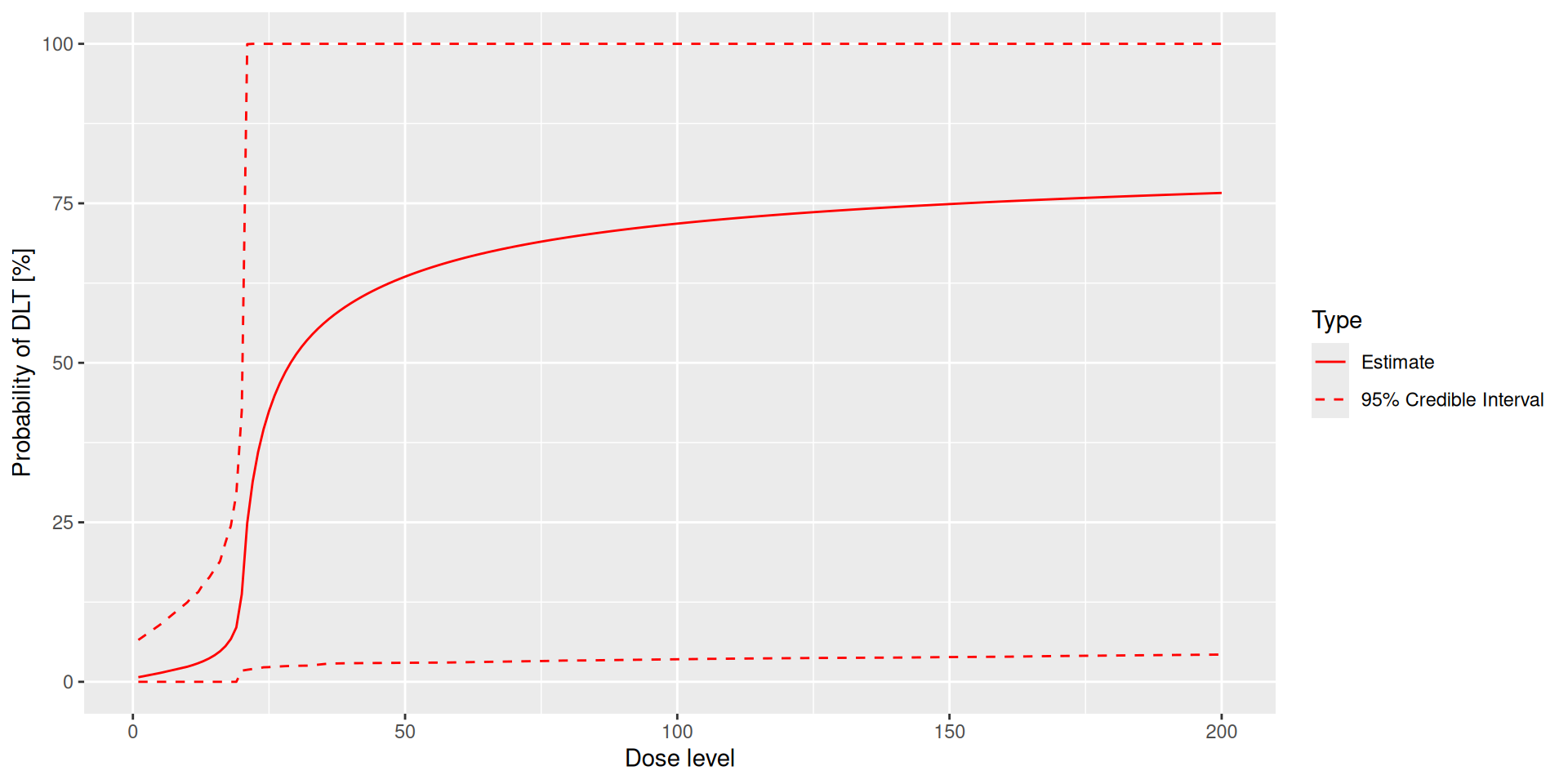
Resulting recommendation example (cont’d)
The joint plot is in the $plot_joint element of the result (target/overdose/unacceptable probabilities and expected loss for each dose):
print(next_best_dose$plot_joint)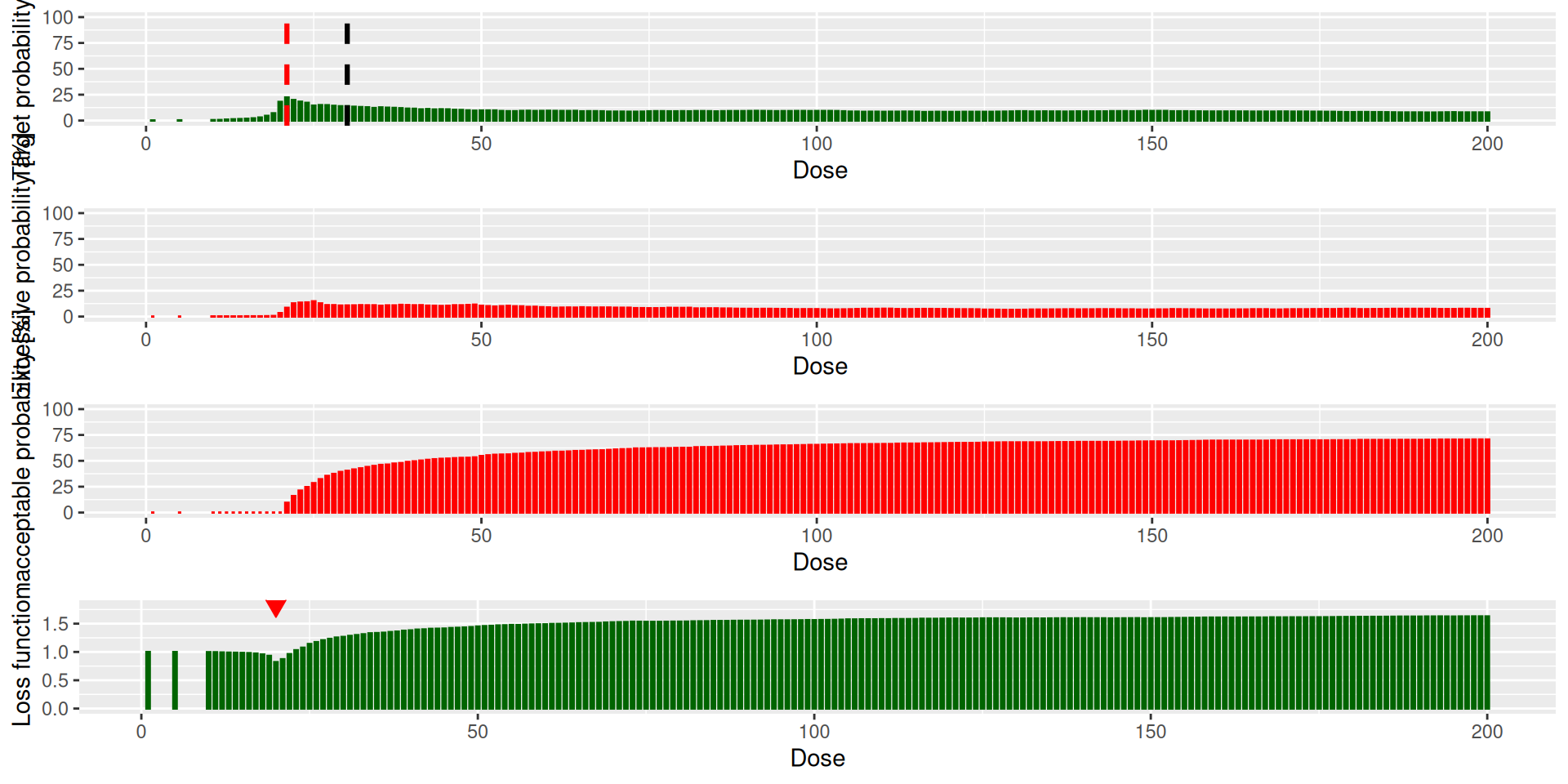
And the value is in the $value element:
next_best_dose$value[1] 20So due to the high probability of overdosing at dose 30, the recommended dose for the next cohort is dose 20, which is the same as the previous cohort.
Adjusted performance
So we need to adjust the prior to be less confident, e.g. by changing the means and the standard deviations of the parameters, changing the reference dose, and checking the plot:
model_adjusted <- LogisticLogNormal(
mean = c(-3, -1),
cov = get_cov(sigma0 = 4, sigma1 = 1, rho = 0),
ref_dose = 100
)
prior_samples_adjusted <- mcmc(model_adjusted, data = empty_data, options = mcmc_options)
plot(prior_samples_adjusted, model_adjusted, empty_data)design_adjusted <- design
design_adjusted@model <- model_adjusted
examine(design_adjusted) dose DLTs nextDose stop increment
1 5 0 10 FALSE 100
2 5 1 1 FALSE -80
3 5 2 NA TRUE NA
4 5 3 NA TRUE NA
5 10 0 19 FALSE 90
6 10 1 15 FALSE 50
7 10 2 5 FALSE -50
8 10 3 1 FALSE -90
9 19 0 37 FALSE 95
10 19 1 28 FALSE 47
11 19 2 17 FALSE -11
12 19 3 10 FALSE -47
13 37 0 61 FALSE 65
14 37 1 51 FALSE 38
15 37 2 31 FALSE -16
16 37 3 22 FALSE -41
17 61 0 122 FALSE 100
18 61 1 90 FALSE 48
19 61 2 50 FALSE -18
20 61 3 38 FALSE -38
21 122 0 189 FALSE 55
22 122 1 128 FALSE 5
23 122 2 97 FALSE -20
24 122 3 70 FALSE -43
25 189 0 197 FALSE 4
26 189 1 200 FALSE 6
27 189 2 154 FALSE -19
28 189 3 122 FALSE -35
29 197 0 195 FALSE -1
30 197 1 200 FALSE 2
31 197 2 199 FALSE 1
32 197 3 172 FALSE -13
33 195 0 180 FALSE -8
34 195 1 200 FALSE 3
35 195 2 199 FALSE 2
36 195 3 200 FALSE 3
37 180 0 181 TRUE 1
38 180 1 200 TRUE 11
39 180 2 200 TRUE 11
40 180 3 200 TRUE 11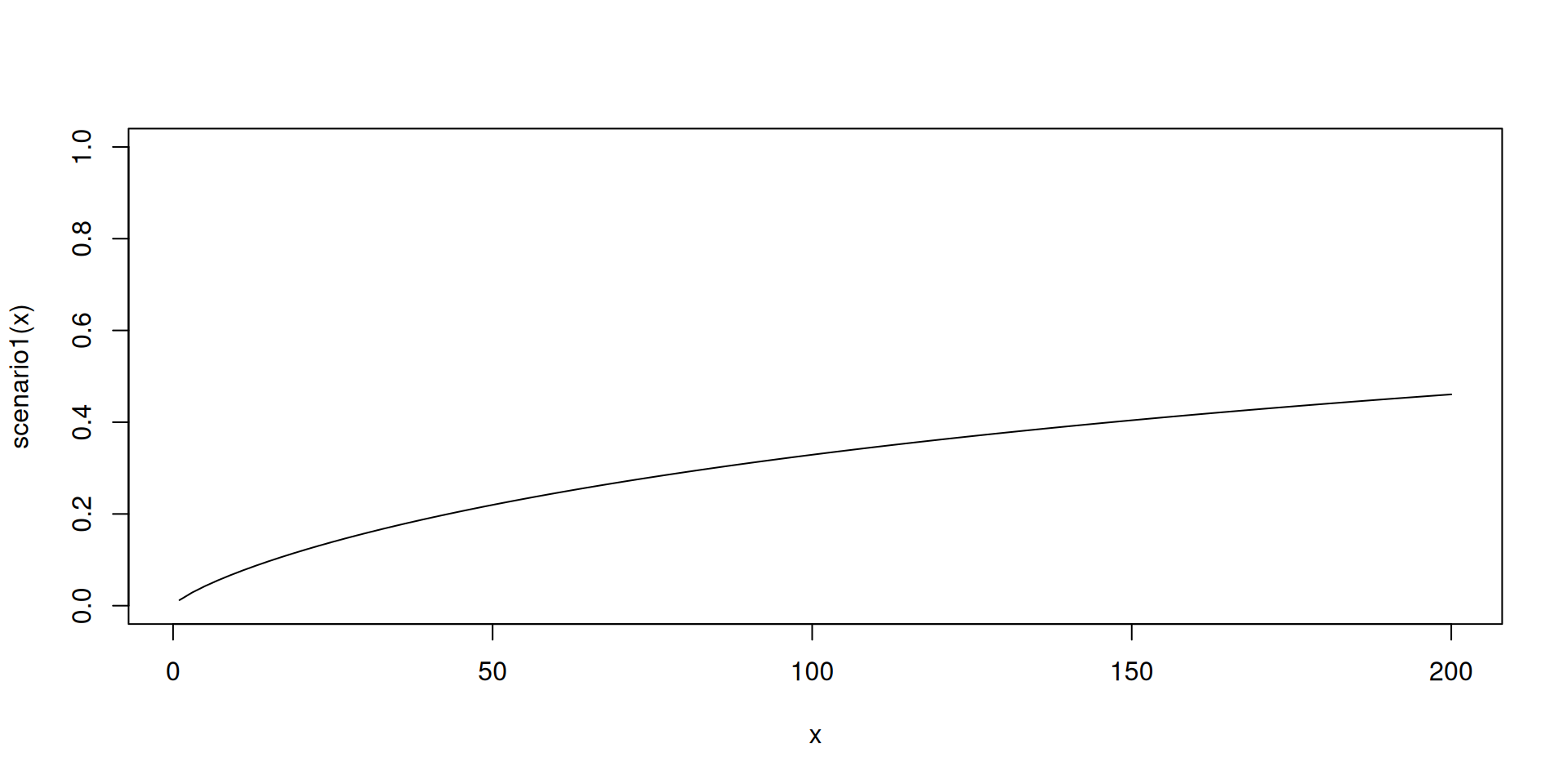
Toxicity scenarios (cont’d)
curve(scenario1, from = 1, to = 200, ylim = c(0, 1))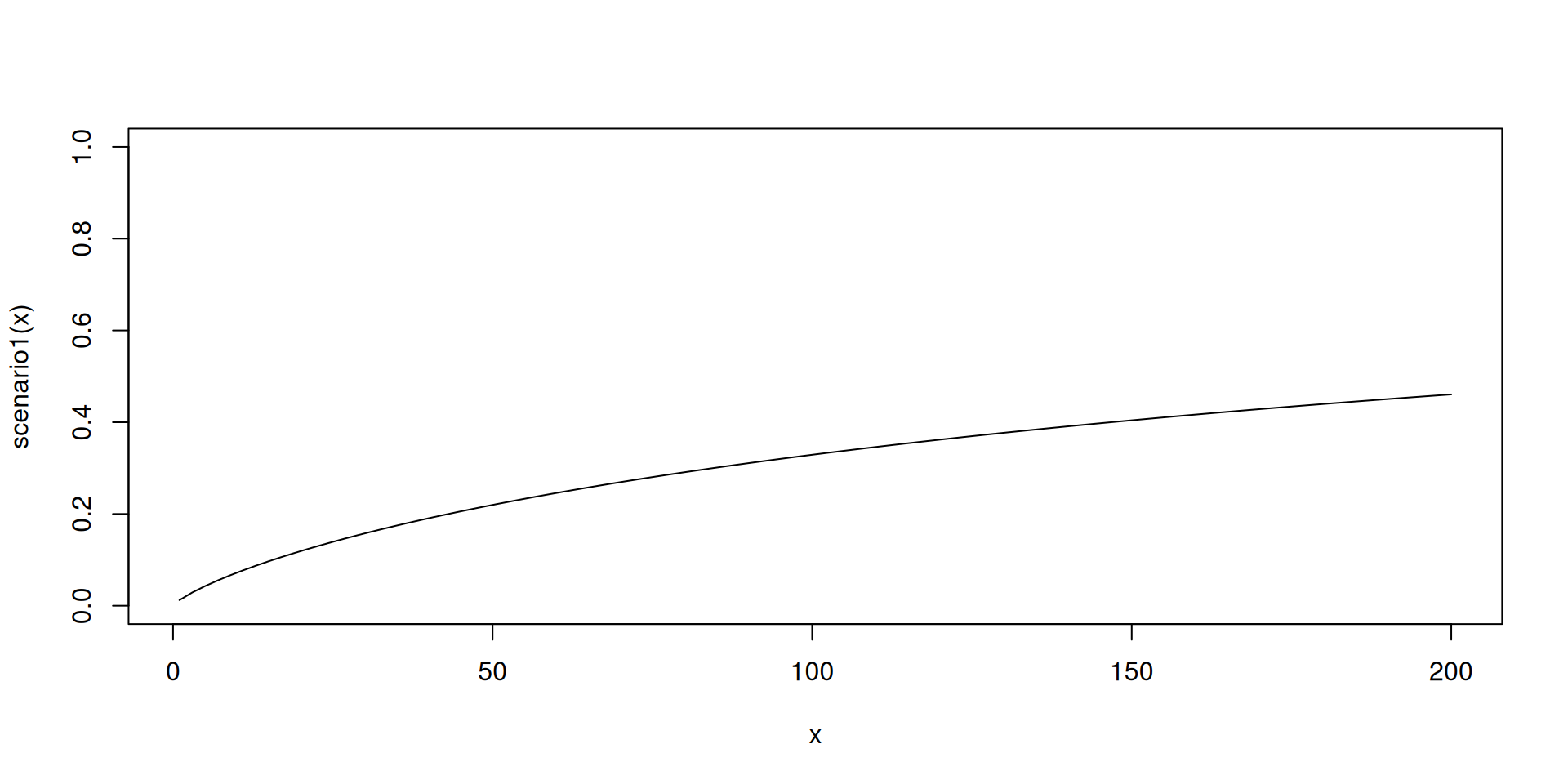
Plotting results
And we can also get more detailed plots of the simulation results with the plot method:
plot(sims)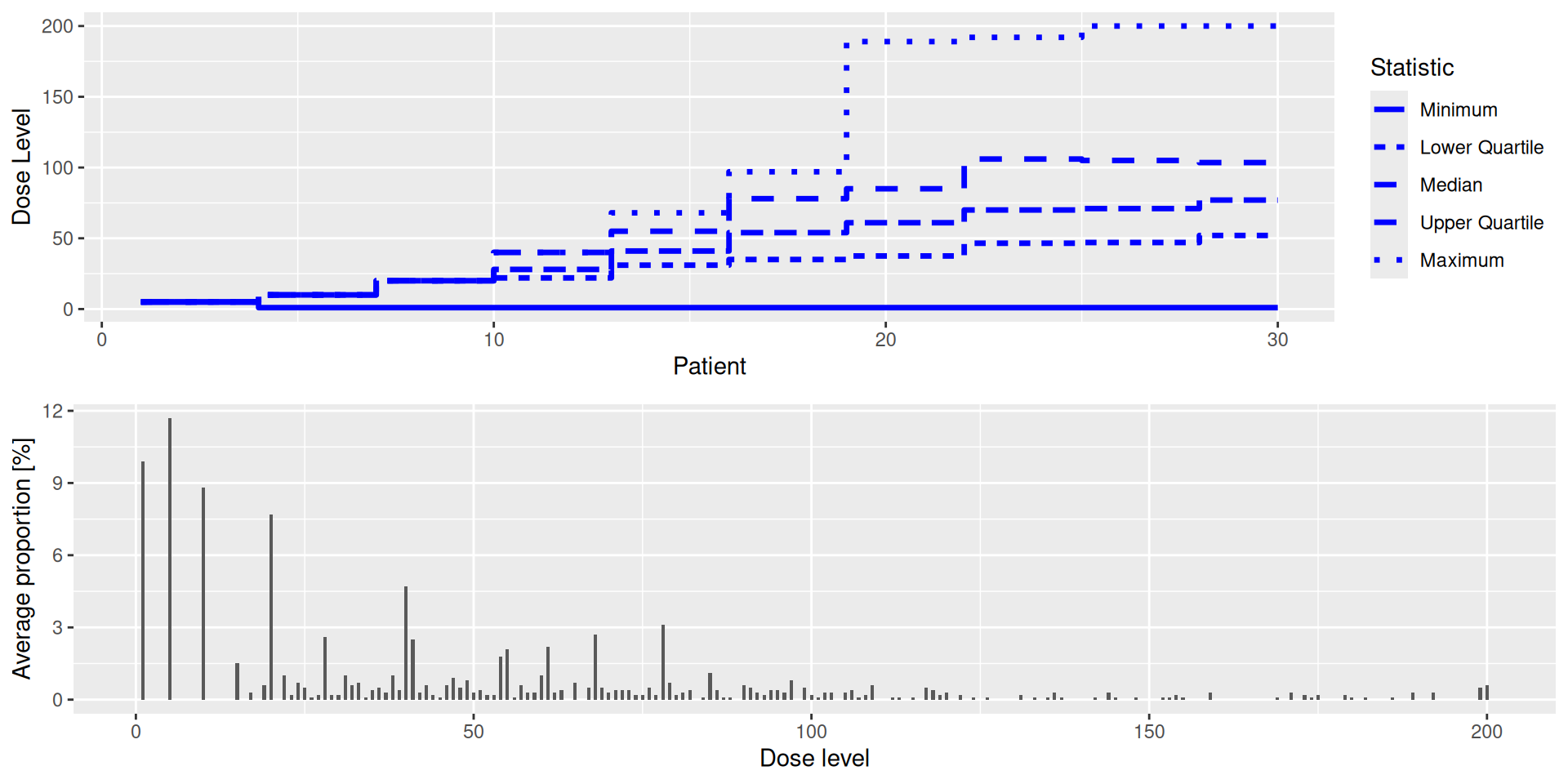
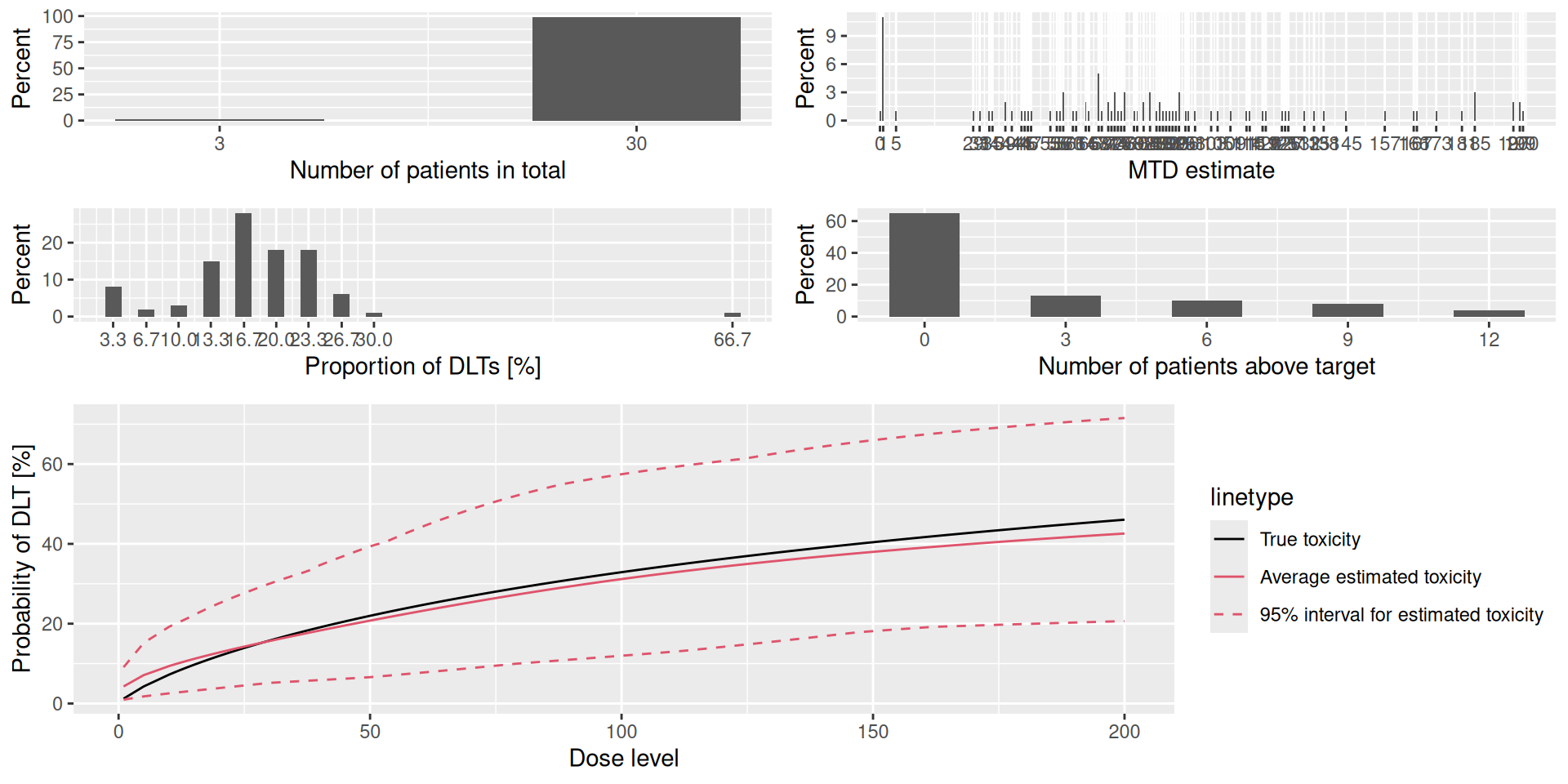
Plotting results (cont’d)
The summary result can also be plotted:
plot(sims_summary)